
The use of large language models and generative AI has significantly impacted computational social science, creating new capabilities and raising new questions for those using software to support social analysis. Key among those is how to evaluate if large models or prompt-based workflows are actually performing better than conventional machine learning. Against this backdrop, we want to propose a more sociotechnical approach to evaluation, one that includes contextual metrics and discussion beyond the standard recall and precision scores. This brief case study shares what happened when we tried this approach on a classifier we’ve built as part of the Counterdata Network’s collaboration with the nonprofit, US-based organization Pregnancy Justice.
Some Background
Building on software systems built as part of the Data Against Feminicide project, the Counterdata Network partners with groups tracking human rights violations via online news to partially automate some of the content discovery and evaluation. In practice, this looks like working together with organizations to train custom ML classifiers that score candidate news articles from online news archives (based on geographic filtering and on keyword matching) for relevance to the violations they want to track.
One of our more recent partnerships is Pregnancy Justice, a national legal advocacy organization that advances and defends the rights of pregnant people, no matter if they give birth, experience a pregnancy loss or have an abortion. Pregnancy Justice’s research team tracks pregnancy criminalization cases across the U.S. in collaboration with academic partners. These are cases charging pregnant people with crimes related to pregnancy, pregnancy loss, or birth. Their extensive and rigorous work is documenting the impact of the Dobbs supreme court ruling, and supporting people brought into the criminal system because of their status as pregnant. Our software system surfaces relevant news articles about cases that fit their focus each week.
 The platform where the Pregnancy Justice team reviews retrieved articles and labels them as relevant or not relevant.
The platform where the Pregnancy Justice team reviews retrieved articles and labels them as relevant or not relevant.
Improving the Model
After collecting and annotating a sample training set and experimenting with ML models, the first version of the model was deployed into the email alerts system to retrieve articles in November 2024. The Pregnancy Justice team reviewed retrieved articles each week and labeled each as Relevant / Not Relevant. When our team analyzed the results, we found the false positive rates were near 40%, meaning that every 2 out of 5 articles returned to the team was not relevant to their search.
From a purely technical standpoint, this was alarming. The model seemed barely better than random chance. As ML researchers, our instinct was to fix the model. We designed three parallel improvement experiments to reduce false positives and boost conventional ML performance metrics. What we learned through the process challenged our concepts about what better even means.
Experiment 1: Should we incorporate better data?
First, we updated our TF-IDF model using a subset of newly annotated data from PJ’s weekly reviews. After incorporating the new data, the model’s false positive rate decreased from 55% to 10%. Our analysis showed that much of the original misclassification was a result of domain-specific terms, such as “midwives,” which appeared frequently in real-world news cases but were absent from our initial manually sourced training set. By incorporating the team’s feedback, the dataset better matched the real-world linguistic context, allowing the simple model to more accurately generalize.
Experiment 2: How about more complicated models?
Our first model used TF-IDF, a method that identifies important words that are common in documents we care about but relatively rare in the entire collection. It’s a relatively simple approach by modern NLP standards, as it counts words rather than attempting to understand semantic meaning.
We hypothesized that more sophisticated embedding models might perform better. Unlike TF-IDF, large language models (LLMs) like BERT, Universal Sentence Encoder, and MPNet are designed to understand the semantic context—the meaning behind sentences. Theoretically, they should capture the nuanced relationships inherent in complex social issues like pregnancy criminalization.
We tested several state-of-the-art embedding models against our current TF-IDF baseline. However, given the ongoing debates about the ecological impacts of LLMs, we decided to evaluate them on more than just accuracy. We also evaluated their environmental and computational costs.
The Trade-off: Accuracy vs. Environmental Impact
The AI community is increasingly recognizing that model performance cannot be divorced from its environmental cost. Extensive research has emphasized the nontrivial energy consumption and associated CO2 emissions from training and deploying LLMs. This environmental footprint —through pollution, resource extraction, and climate change— disproportionately affects marginalized communities, many of the very communities Pregnancy Justice serves. As a result, our team was committed to prioritize environmental sustainability. With this in mind, we evaluated not just accuracy metrics but also running time and CO2 emissions (estimated using the codecarbon package).
| Embedding Model | FPR | Time | CO2 Emissions |
|---|---|---|---|
| TF-IDF (w/ new data) | 0.12 | 1x | <1 mg |
| MPNet | 0.07 | 105x | >10 mg |
| USE | 0.07 | 31x | >5 mg |
| Sentence-BERT | 0.09 | 18x | >10 mg |
| mxbai-embed-large | 0.23 | 353x | >100 mg |
Model performance (FPR) and computational cost (time, CO₂ emissions) across embedding approaches. FPR = false positive rate (lower is better);
Our results show that while some embedding models achieved low false positive rates, the computational costs were staggering. The mxbai-embed-large model, for example, took 353 times longer to run and emitted significantly more carbon than our original model. The accuracy gains were small, especially compared to the retrained TF-IDF model, with substantial environmental costs. This matches findings from other research, where simpler models such as static embeddings have been shown to perform comparably on digital humanities tasks while requiring significantly less compute (Ehrmanntraut et al., 2021).
After discussing these results with the Pregnancy Justice team, we reached a critical conclusion that the marginal gain in accuracy does not justify the increased environmental and computational harm.
Experiment 3: How confident should the models be?
Our final experiment involved adjusting the model’s decision threshold. Our model outputs a probability score between 0 and 1 for each article, indicating the model’s confidence that the article is relevant. For the first model we used a threshold of 0.5: articles scoring above 0.5 were classified as relevant.
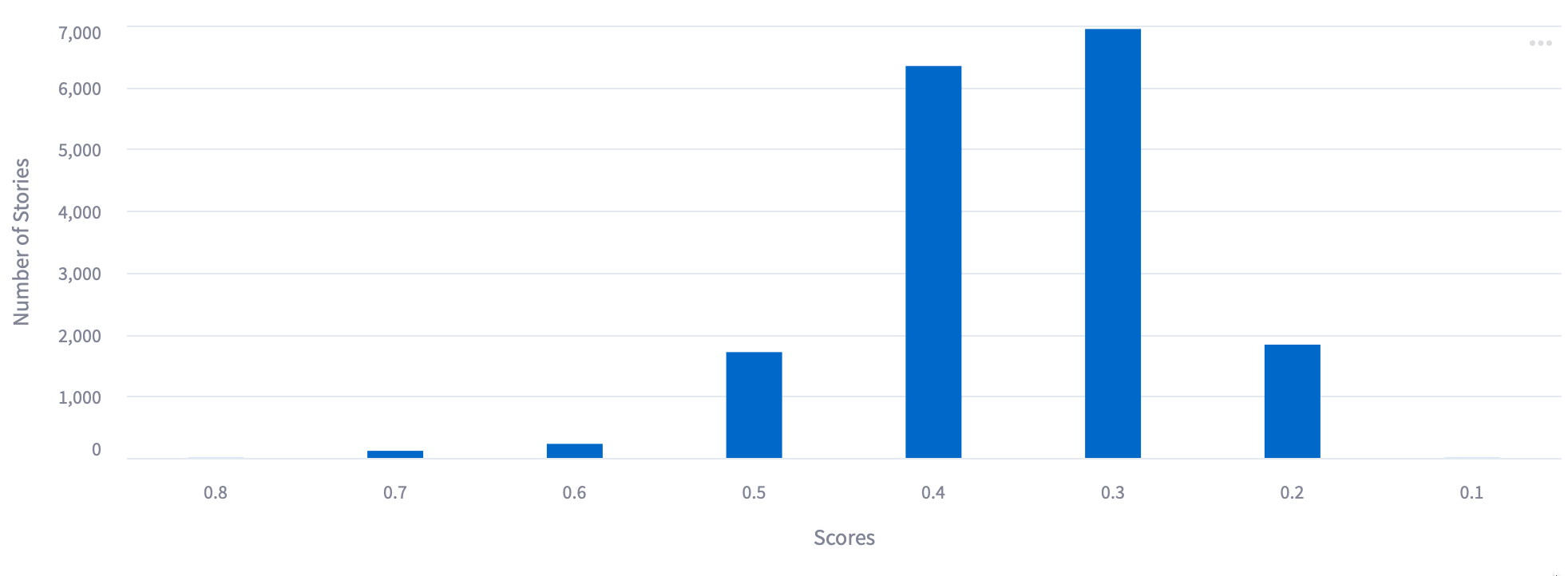 Histogram showing the distribution of scores on stories from the first model. Note the majority after under 0.5, our threshold for including in results sent to the team.
Histogram showing the distribution of scores on stories from the first model. Note the majority after under 0.5, our threshold for including in results sent to the team.
We hypothesized that If the threshold were raised, e.g. to 0.7 or 0.8, the model would reduce false positives by only returning articles it was very confident about. Our experiments confirmed this, but also showed a tradeoff: a stricter threshold means missing some truly relevant articles.
When we presented this tradeoff to the Pregnancy Justice team, they offered a surprising insight: they wanted the false positives.They explained that reviewing even the false positive articles, those not directly about pregnancy criminalization, was actually valuable. These articles helped them understand the broader landscape: adjacent policy discussions, related criminal justice issues, and the wider context in which pregnancy criminalization occurs. What we labeled as irrelevant from a technical standpoint was often relevant from a strategic advocacy standpoint.
This insight fundamentally reframed our evaluation. The model wasn’t just a filter to remove noise—it was a discovery tool that exposed the team to a broader information ecosystem. The “noise” contained signals we hadn’t anticipated.
Towards Sociotechnical and Community-Centered ML Evaluation
This case study highlights three critical lessons for evaluating ML systems with stakeholders and communities:
- Bigger isn’t always better: Improving the training data might yield far significant improvements than increasing model complexity.
- Let communities define success: Technical metrics like accuracy and false positive Rates are proxies for utility. What counts as correct output depends on contexts, workflows, and values that these metrics cannot capture. We recommend co-designing metrics and success criteria with the people who will use the system.
- Evaluate the System, Not Just the Algorithm: Efficiency is an ethical metric. By quantifying the time and CO2 costs, we made a value judgment that aligned our technical infrastructure with our project’s justice-oriented values.