
How effective are existing tools for extracting author information from global online news? Author extracton is a key task in media research that supports a number of different types of research questions. We’ve hesitated to support this broadly in Media Cloud, because our past evaluations of off-the-shelf software solutons haven’t performed consistently and related ethical concerns about weaponizaton against journalists. We decided to revisit this quesions last year and just published a pre-print to document our results. Read “Author Unknown: Evaluating Performance of Author Extraction Libraries on Global Online News Articles” by Sriharsha Hatwar, Virginia Partridge, myself, and Fernando Bermejo.
Given the diversity of languages and content styles in today’s news landscape, researchers need reliable ways to gather accurate metadata for large-scale media analysis. However, many of the author extraction libraries were designed for English or other commonly studied languages, often neglecting the nuanced challenges that multilingual content poses.
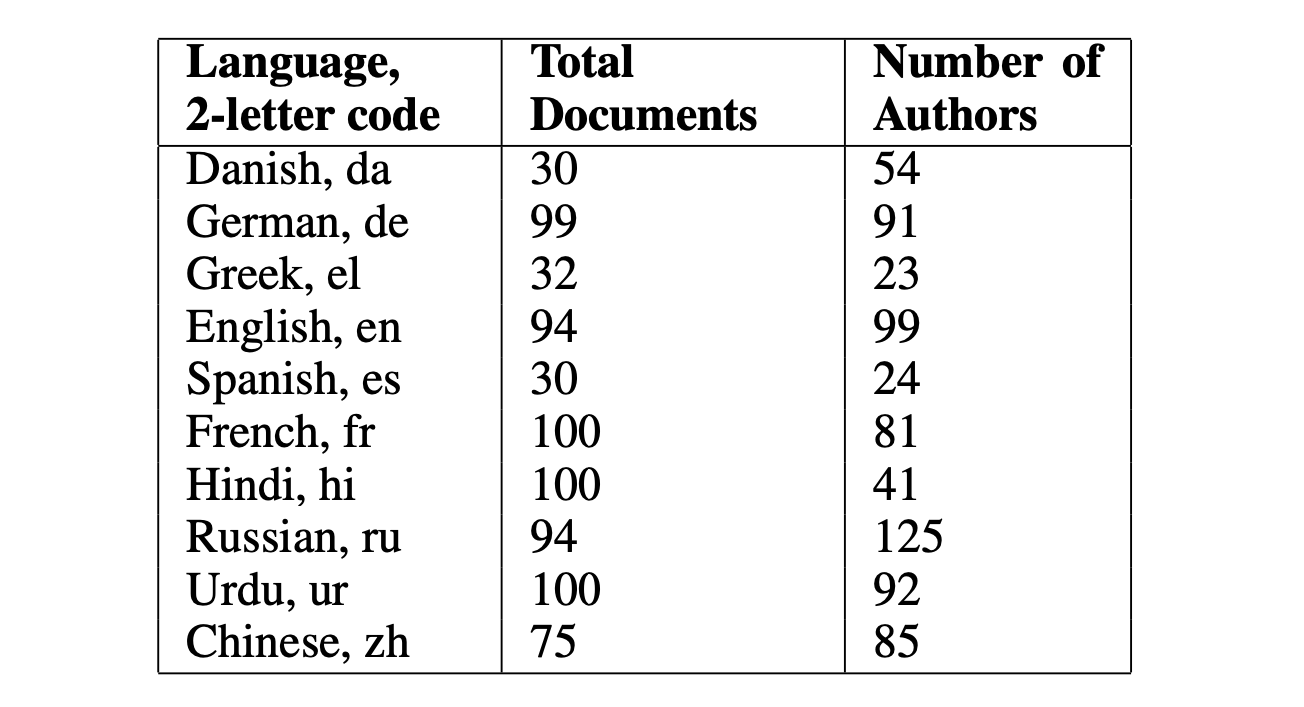 Counts of documents and number of author annotations total in the final evaluation dataset.
Counts of documents and number of author annotations total in the final evaluation dataset.
Our study introduces a new multilingual dataset to evaluate several popular libraries (Newspaper3K, Trafilatura, news-please, Go-readability, and ExtractNet). The results reveal an wide range of performance outcomes. Libraries like Go-readability and Trafilatura stood out as the most effective in certain scenarios, but the effectiveness of each tool varied considerably based on language and region. For instance, while one library might perform well on English or European-language news, it could struggle with languages that have less standardized structures or different metadata conventions. This highlights a critical shortfall: these tools, though popular, aren’t yet universal solutions for a diverse, global media landscape.
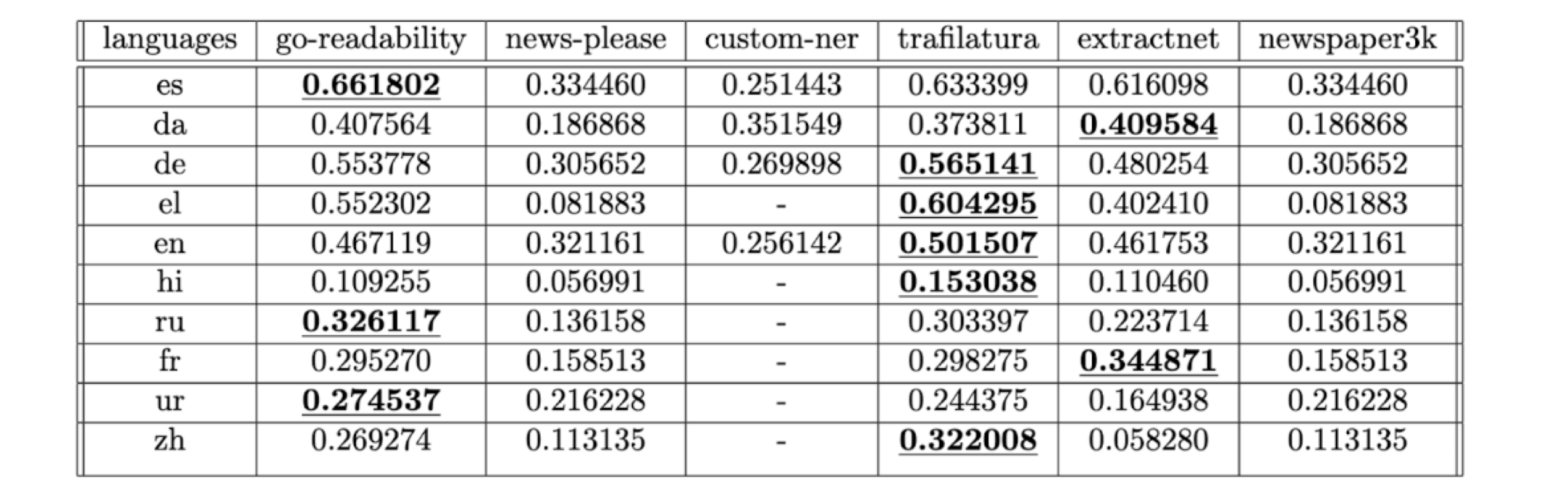 Rouge-1 scores for each library in each language. Higher is better. Dashes indicate instances of no character overlap.
Rouge-1 scores for each library in each language. Higher is better. Dashes indicate instances of no character overlap.
From a practical standpoint, our findings suggest that researchers working with non-English or multilingual datasets should prioritize testing and validating their tools within their specific research context before embarking on large-scale data collection. That’s not an especially surprisinng result… “your mileage may vary.” The research also points to a promising direction for future work—developing multilingual models or even language-specific modules within existing libraries that can reliably handle a wider range of text sources. A clear missing piece here is a comparison to results from recently-released generative AI models; our study was carried out before those surged to the fore-front. Consider that fodder for a future blog post.
Thanks to the author team and the broader set of people who volunteered their time and language expertise to help us build the evaluaton dataset. For those interested in the technical details, the full paper delves deeper into the evaluation methods and our recommendations for best practices in multilingual media analysis. We hope our new dataset and this evaluation help push this area of software development forward.
Read “Author Unknown: Evaluating Performance of Author Extraction Libraries on Global Online News Articles” on arXiv.
